

Veeam v13 Software Appliance HA構成で「自動フェイルオーバー」検証やってみた!
Veeam v13でLinuxのSoftware Applianceがリリースされました。 ベータテストの目玉の新機能として、2台のアプライアンスでアクティブスタンバイのHA構成が組めるようになり、世界中のVeeamブロガーが評価記事を書いています。
ただし、最初の実装としては、手動操作によりスタンバイノードにスイッチオーバーする仕様でした。そして今回、2025/11/21 に正式リリースされた v13.0.1では、HA機能が拡張され、Veeam ONEによるWitness(監視)で、自動的にフェイルオーバーが可能になったことが、新機能リリースノートにこっそりと記載されていました。
Users can perform one-click failover and failback for both unplanned (primary backup server is already down) and planned outages (when primary backup server is still active, but a natural disaster is coming).
While users of VDP Advanced with Veeam ONE deployed can in addition enjoy automated failovers with Veeam ONE serving as the cluster witness.引用:Veeam Backup and Replication v13 What’s New
ユーザーは、計画外の障害(プライマリバックアップサーバーがすでにダウンしている場合)と計画的な停止(プライマリバックアップサーバーはまだアクティブだが自然災害が迫っている場合)の両方について、ワンクリックでフェイルオーバーとフェイルバックを実行できます。さらに、Veeam ONEを展開したVDP Premium(※)のユーザーは、Veeam ONEがクラスターのウィットネスとして機能することで、自動フェイルオーバーを利用できます。
To be able to use HA cluster, you must install the Veeam Data Platform Premium License.HAクラスタを使用するには、Veeam Data Platform Premiumライセンスをインストールする必要があります。
この検証は まだ誰もやっていないだろう、ということで早速検証してみました!
今回のブログでは、その検証レポートとして、下記の内容を共有します。
HA構築の流れ
注目の「Veeam ONE連携による自動フェイルオーバー」の挙動
検証で直面した課題(スプリットブレイン)について

1. 検証環境とHA構成の基本
1-1. 検証構成
Veeam v13 の Software Appliance(Linuxベース)では、2台のノードを使用してアクティブ・スタンバイのHAクラスタを構成できます。
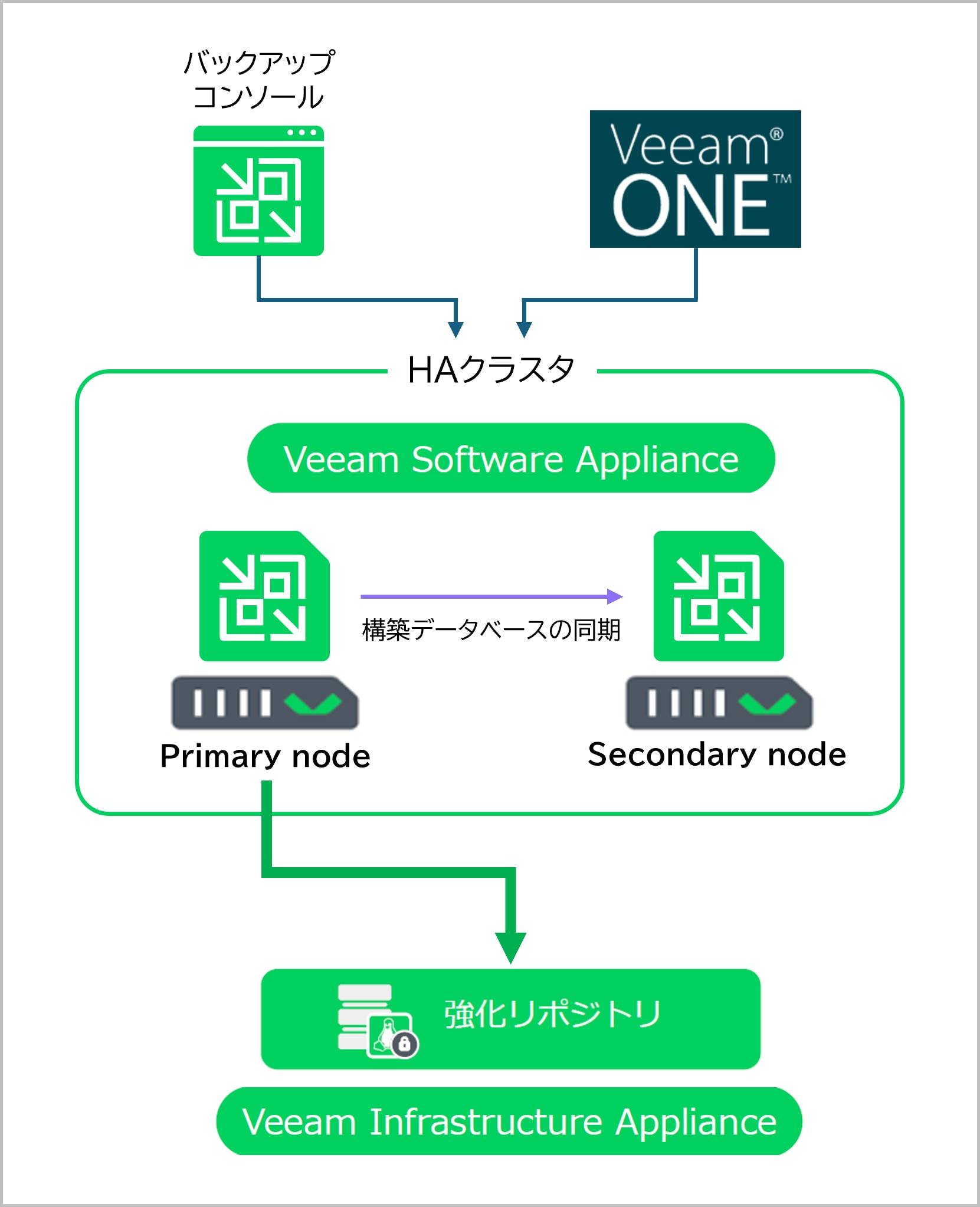
図:検証構成(HAクラスタ)
- 検証環境
Primary Node | : vsa13a (192.168.0.11) |
|---|---|
Secondary Node | : vsa13b (192.168.0.12) |
Cluster VIP | : 192.168.0.23 |
Management | : Veeam ONE v13(Witnessとして機能) |
1-2. HAクラスタ構成の”ハマり”ポイント
構築ウィザード自体はシンプルですが、一つ重要な前提条件があります。
それは「ローカルリポジトリの削除」です。
デフォルトで作成されるローカルリポジトリが残っていると、HAクラスタの作成ウィザードが進まない仕様になっています 。
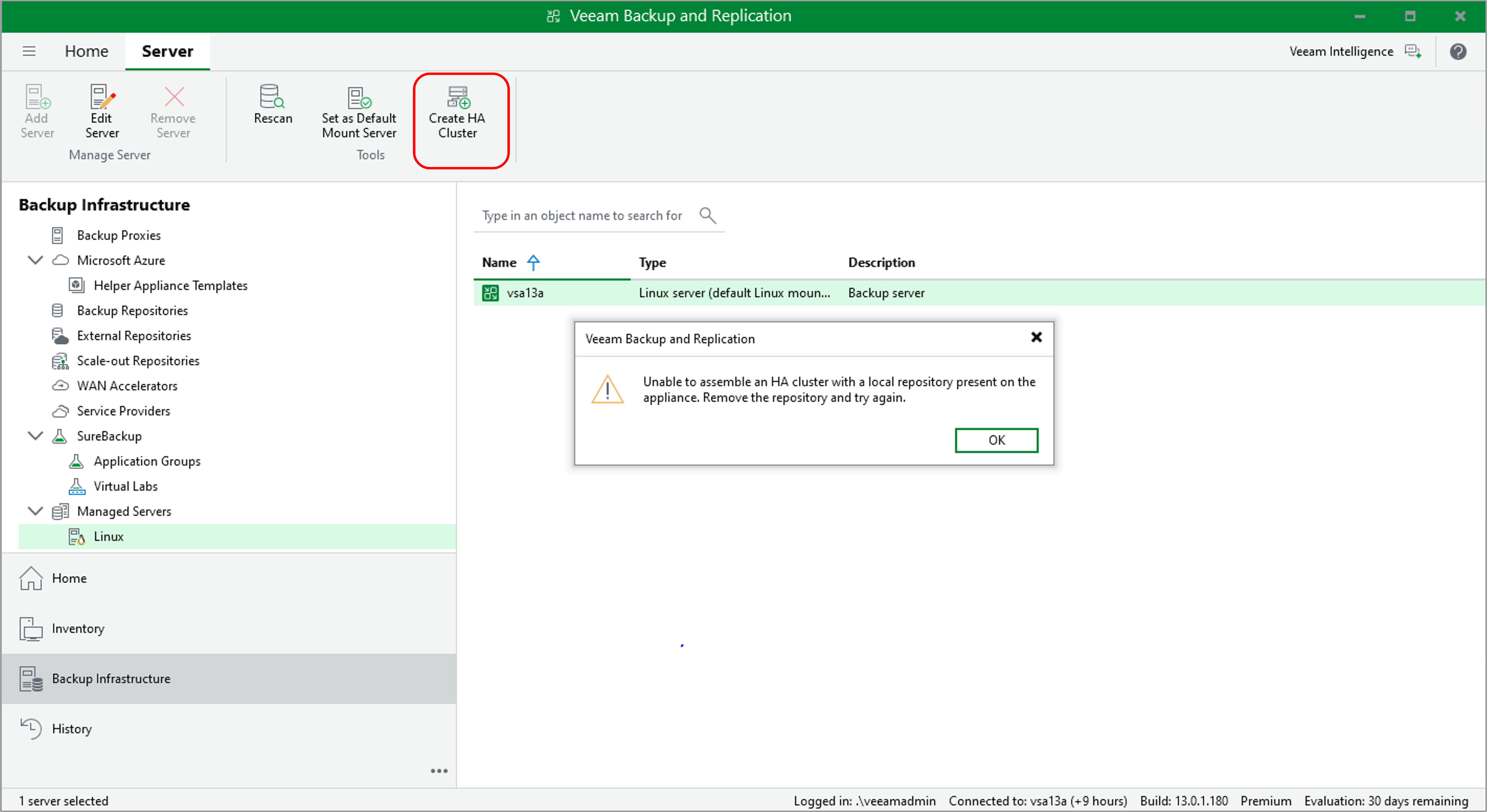 図:HAクラスタ作成中に発生するエラー(ローカルリポジトリ削除前)
図:HAクラスタ作成中に発生するエラー(ローカルリポジトリ削除前)
1-3. HAクラスタの構築手順
前出の"ハマり"ポイントを踏まえ、HAクラスタの構築手順は下記のとおりです。
- Linux強化リポジトリなどの外部リポジトリを追加する。
- デフォルトのローカルリポジトリを削除する。
- 「Create HA Cluster」ウィザードを実行。
これらをクリアすると、クラスタ用のDNS名と仮想IP(VIP)を指定するだけで、数分でセットアップが完了します。
 図:事前準備(ローカルリポジトリの削除)
図:事前準備(ローカルリポジトリの削除)
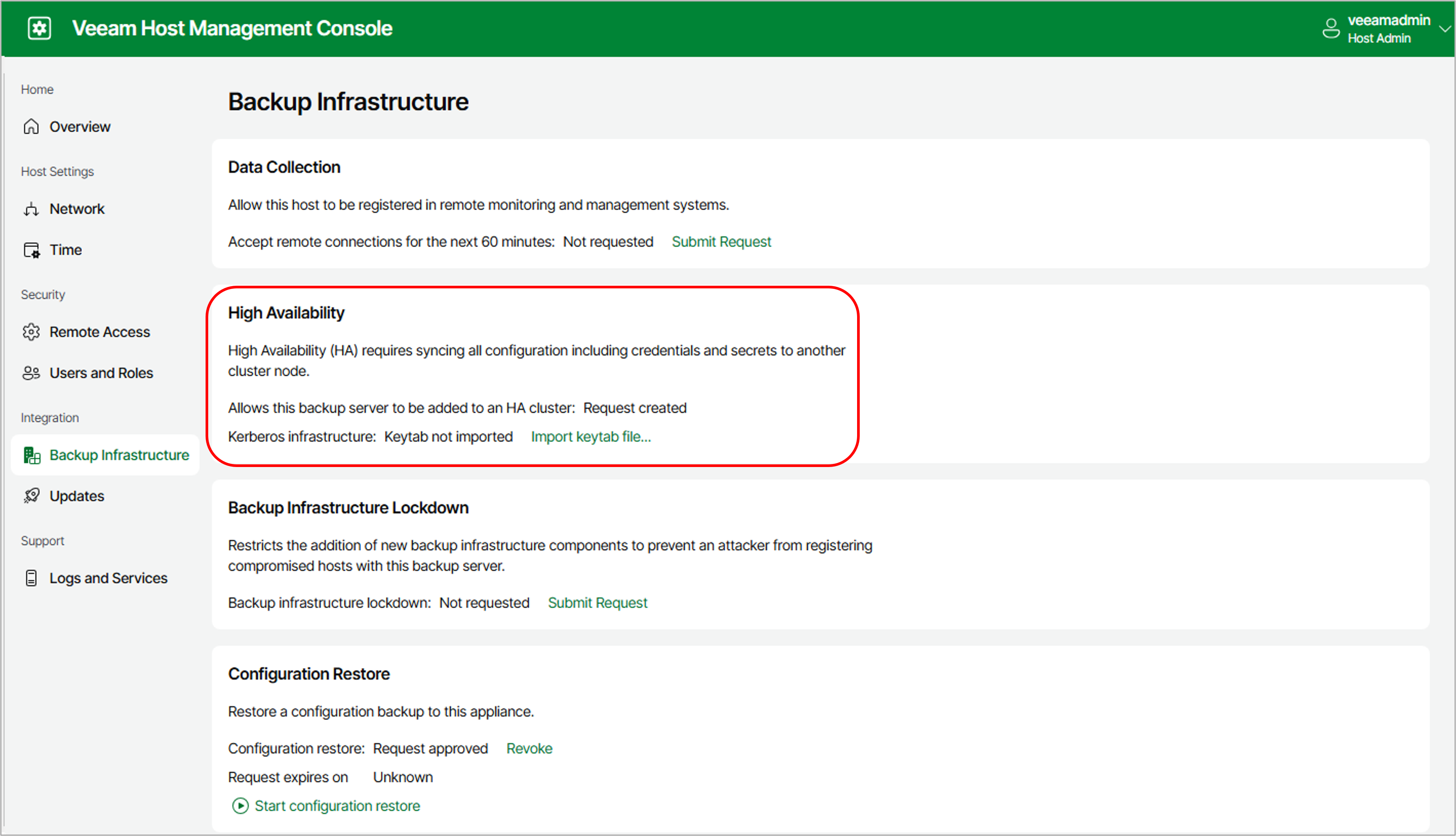 図:Host Management Consoleからリクエストをあげる
図:Host Management Consoleからリクエストをあげる
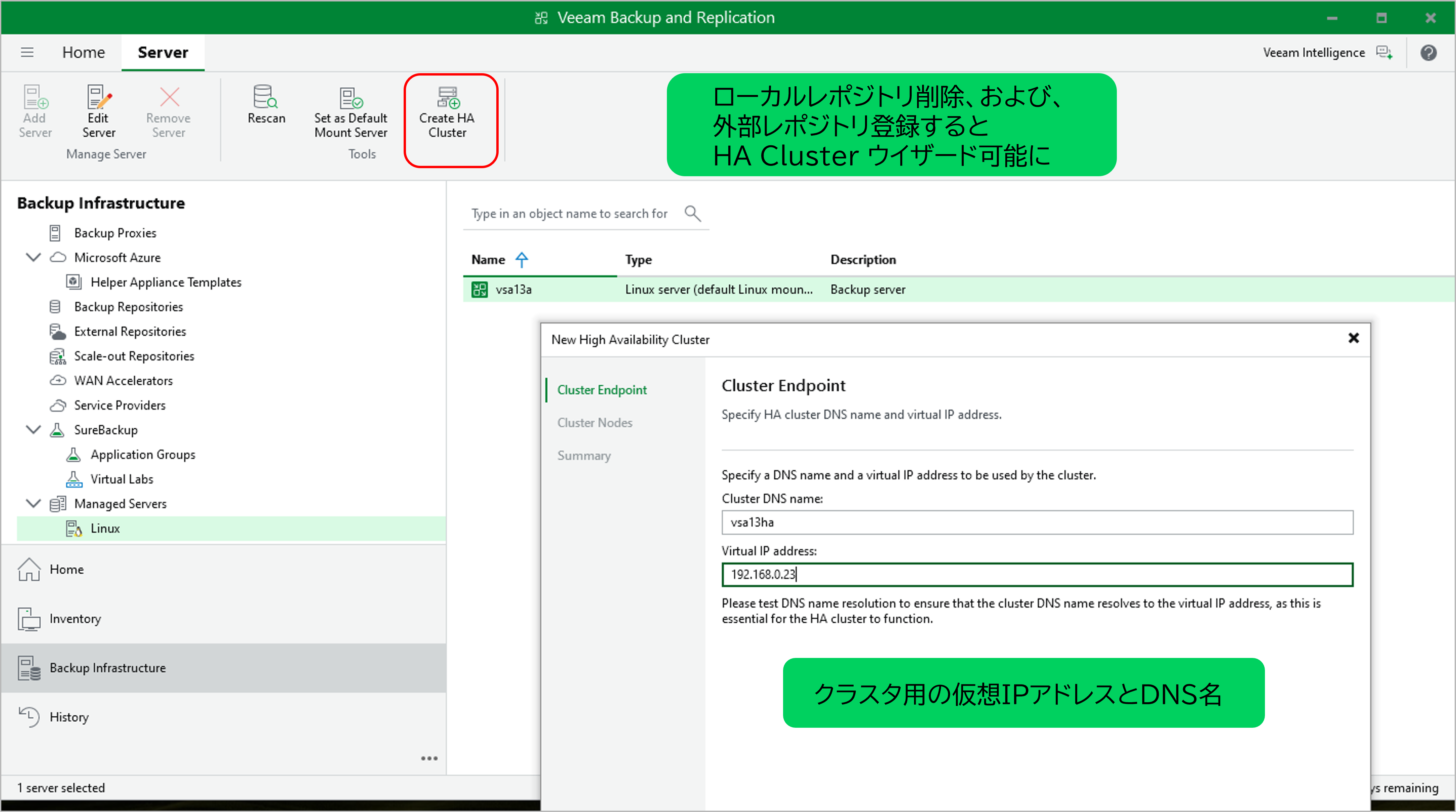 図:ローカルリポジトリ削除するとエラーなくウィザードが進む
図:ローカルリポジトリ削除するとエラーなくウィザードが進む
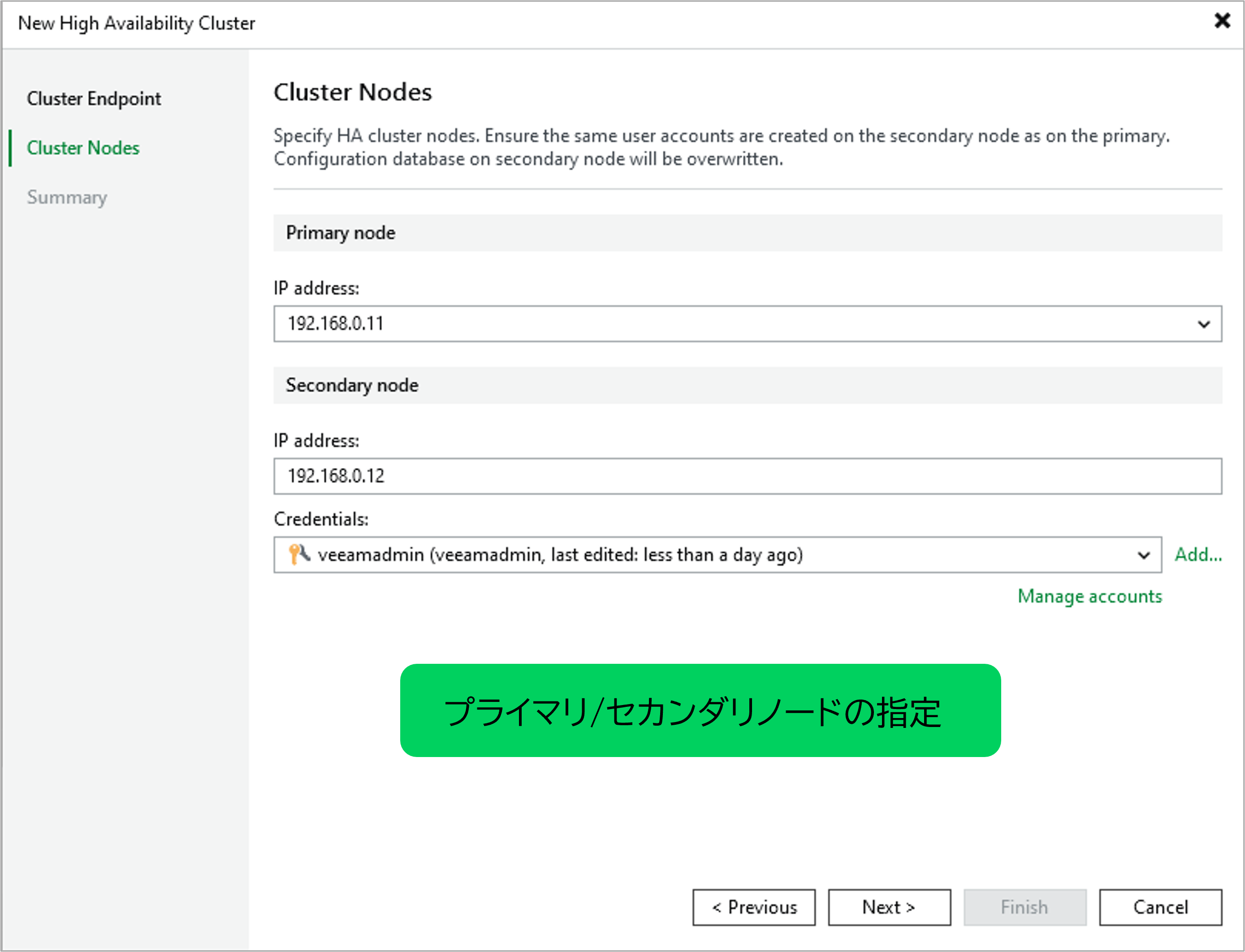 図:HAクラスタ作成ウィザード(プライマリ/セカンダリノードの指定)
図:HAクラスタ作成ウィザード(プライマリ/セカンダリノードの指定)
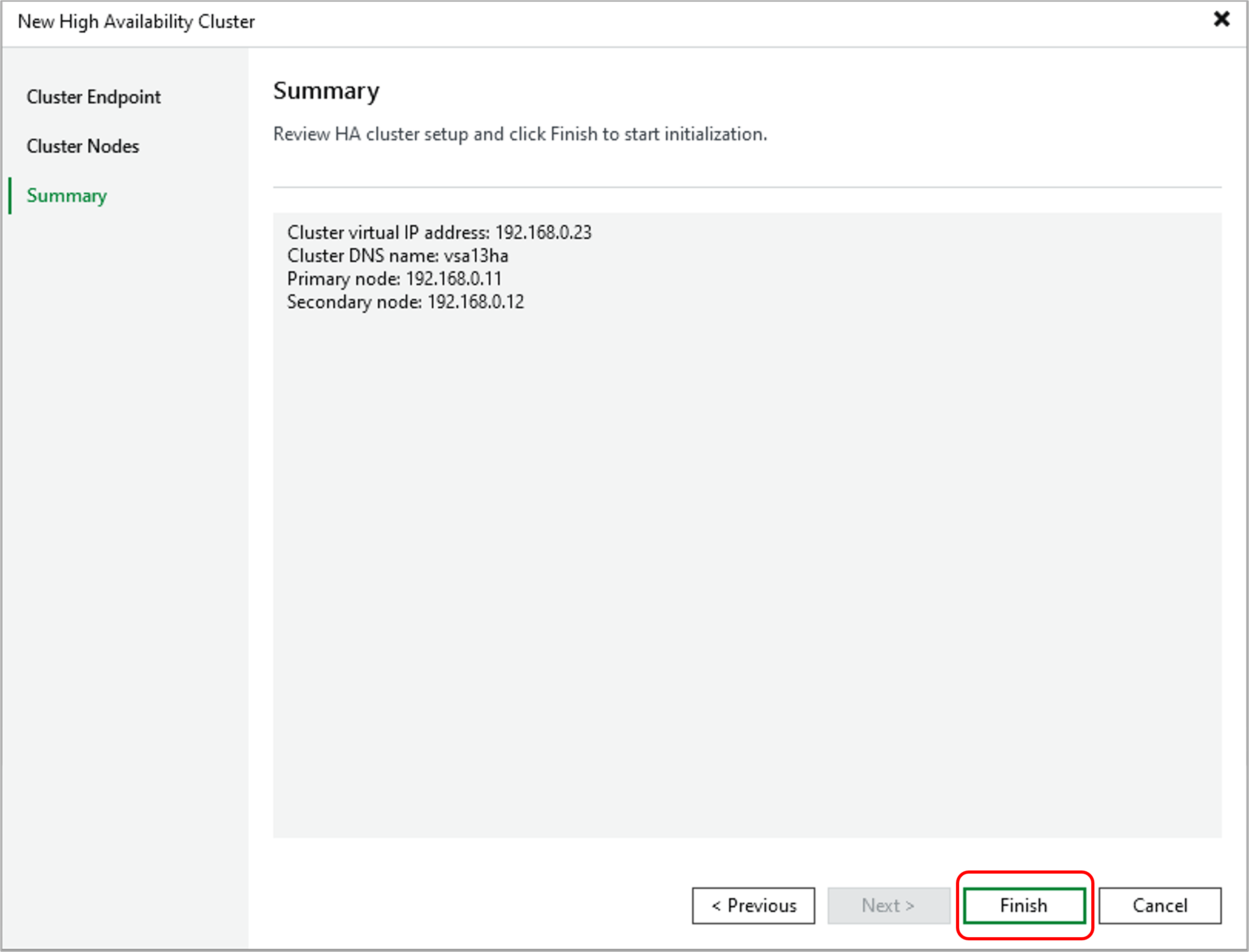 図:HAクラスタ作成ウィザード(設定内容確認)
図:HAクラスタ作成ウィザード(設定内容確認)
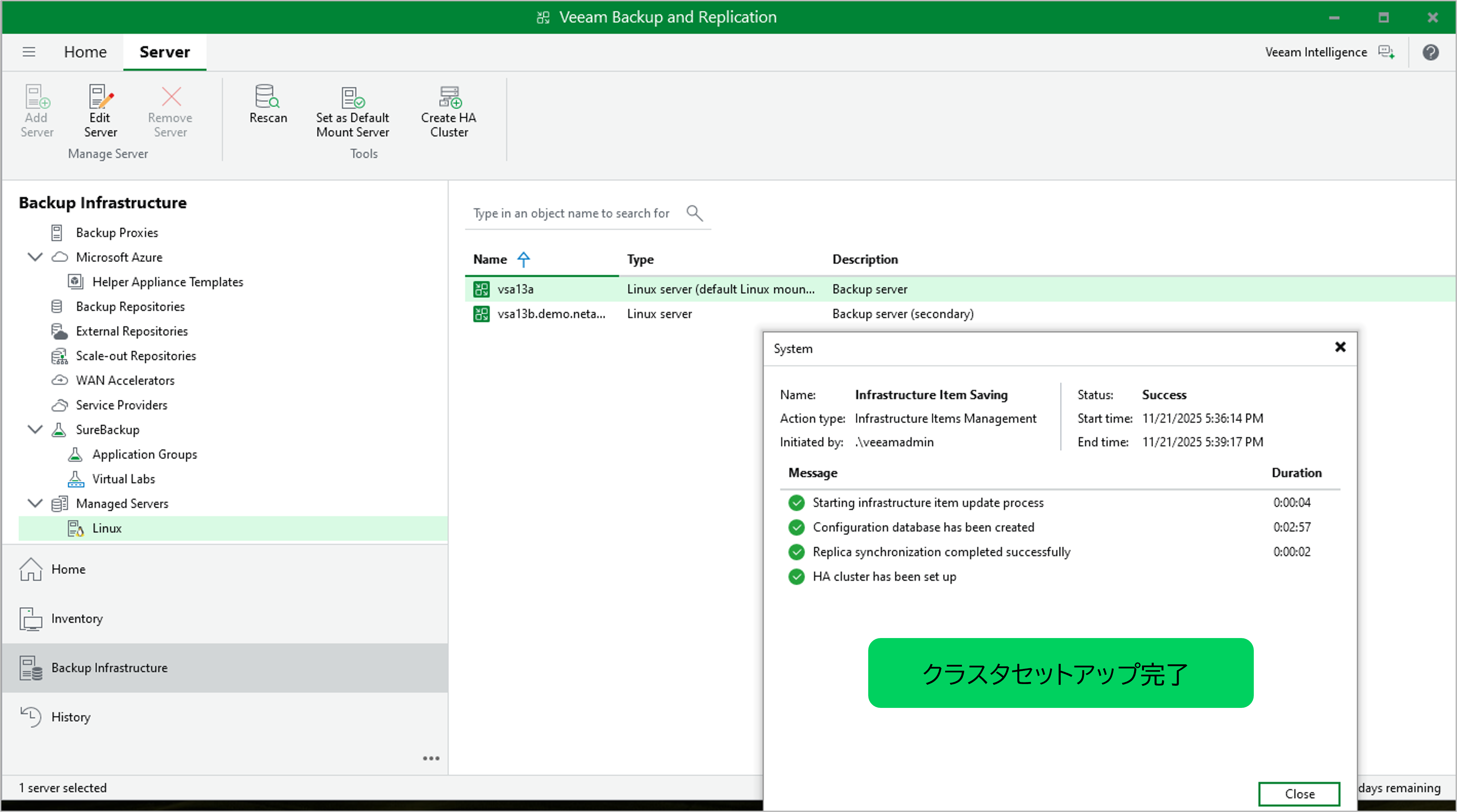 図:HAクラスタセットアップ完了
図:HAクラスタセットアップ完了
2. 手動スイッチオーバーの確認
自動フェイルオーバーを試してみる前に、まずは基本的な手動切り替えを確認しましょう。
VBRコンソールから「Switchover to Another Node」を選択することで任意のタイミングでActive/Standbyの役割を切り替えることができます。
この操作は、メンテナンスの時などに有用です。
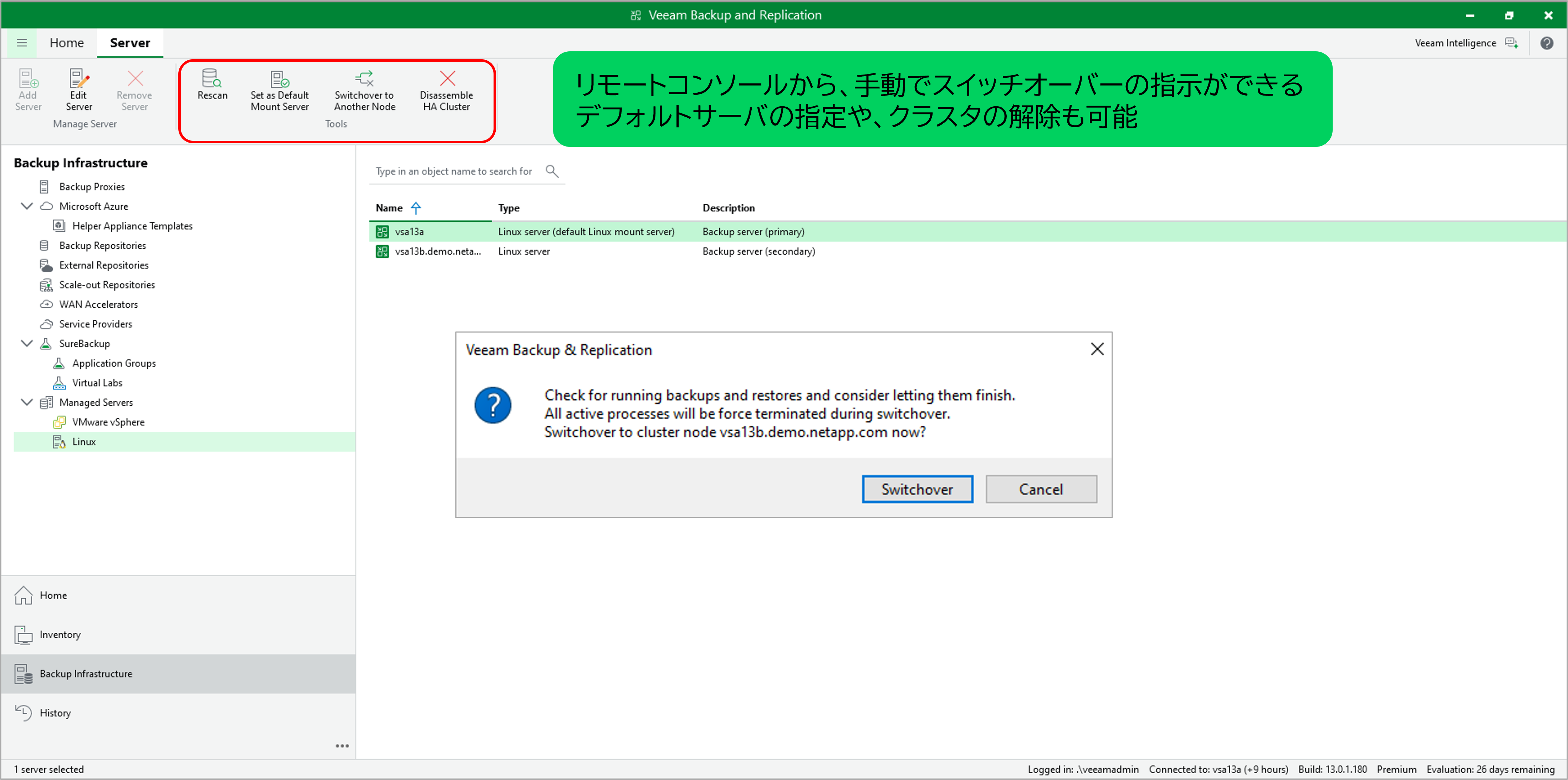 図:VBRコンソールから手動スイッチオーバ―を実行
図:VBRコンソールから手動スイッチオーバ―を実行
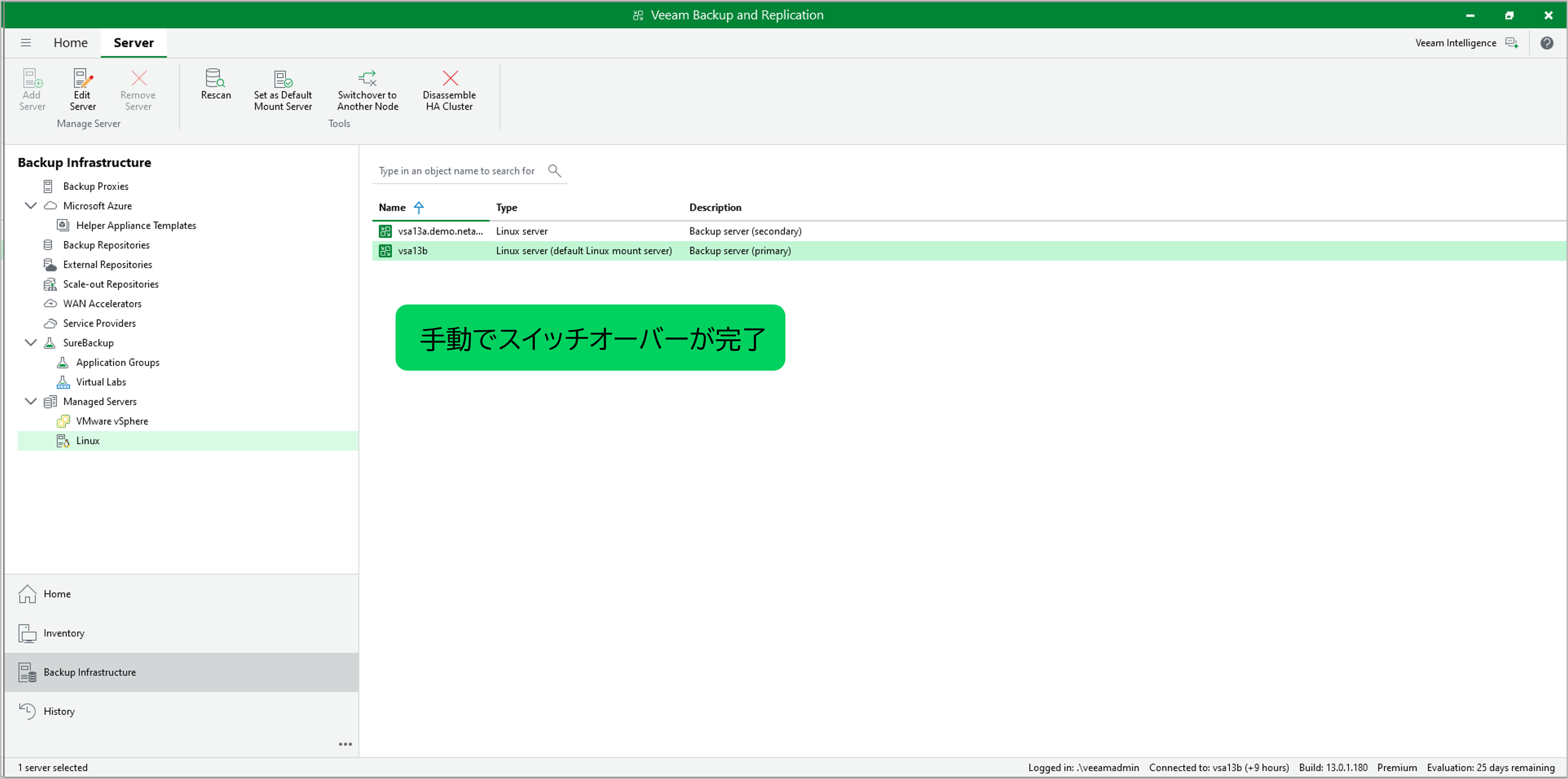 図:手動スイッチオーバーが正常に完了
図:手動スイッチオーバーが正常に完了
3. 目玉機能:Veeam ONE連携による「自動フェイルオーバー」
いよいよ、ここからが本題です。
v13.0.1以降、Veeam ONEを「Witness(監視役)」として使用することで、プライマリノードに障害が発生した際、自動的にセカンダリへ切り替えることが可能になりました 。
3-1. 自動フェイルオーバー設定手順
- 1.HAクラスタへのアクセス許可
Host Management Consoleでリモートモニタリングの許可リクエストを出します 。
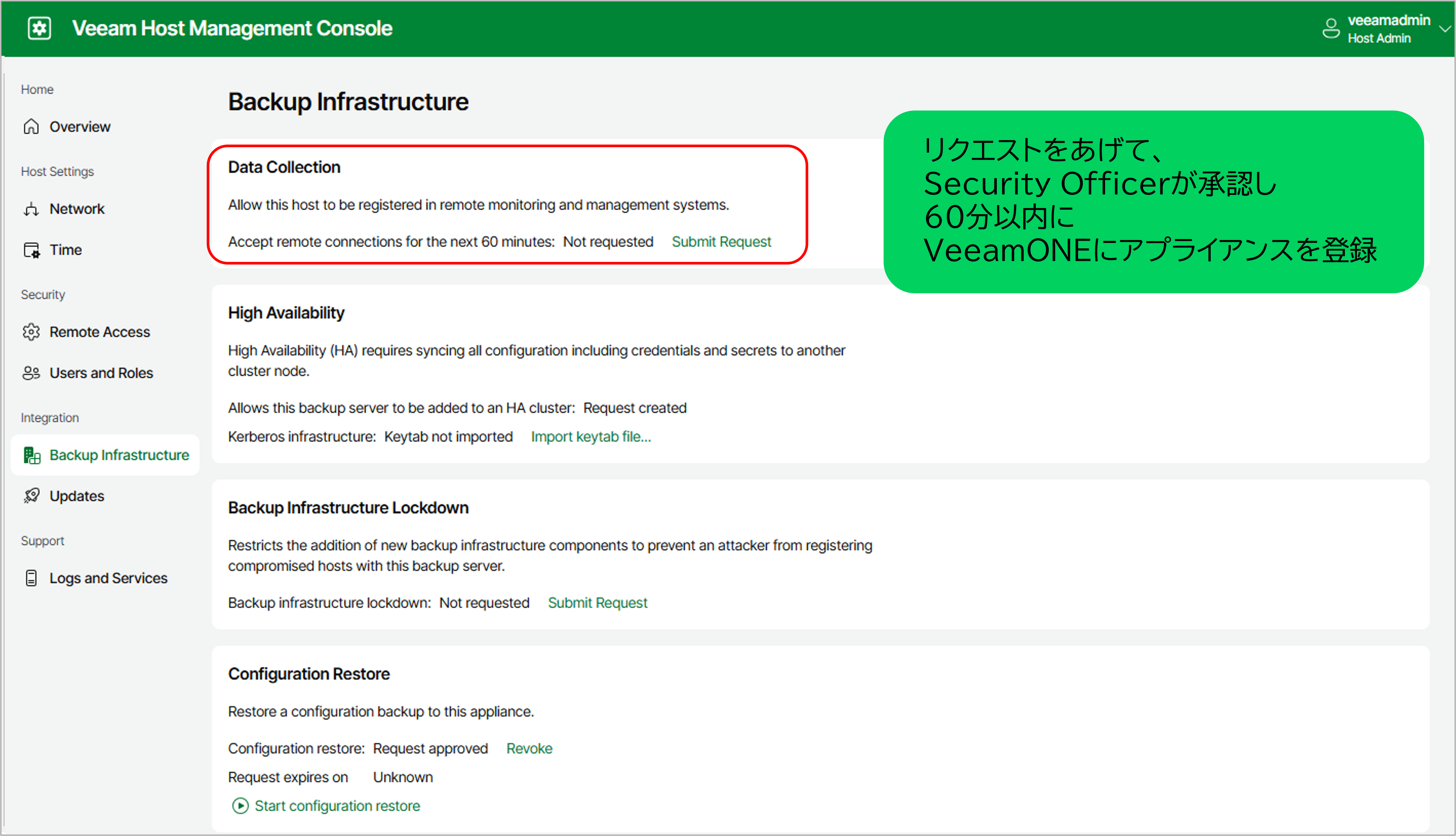 図:Host Management Consoleからリクエストをあげる
図:Host Management Consoleからリクエストをあげる
- 2.Veeam ONEへの登録
Veeam ONEにサーバを追加すると、自動的に「High-availability cluster」として認識されます 。
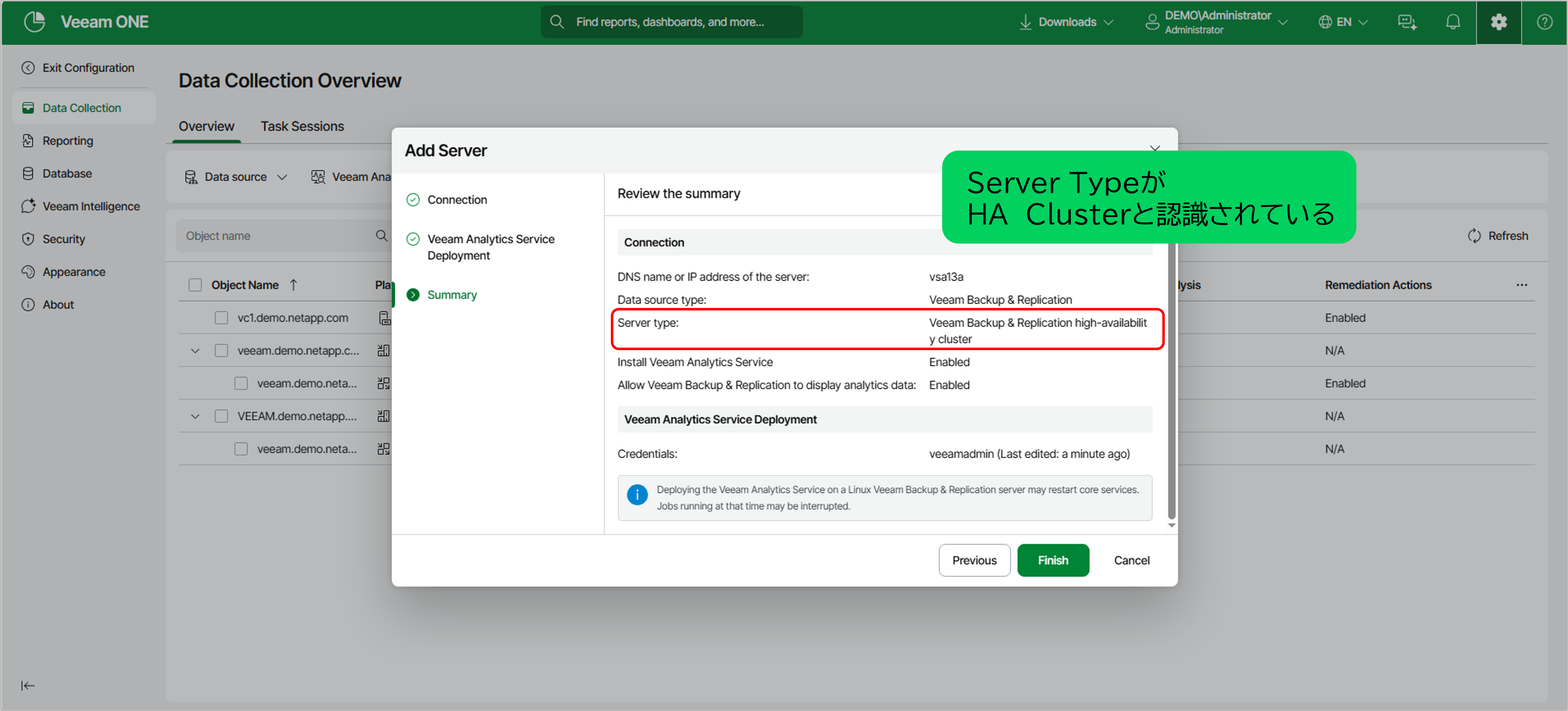 図:Veeam ONEにサーバ(HAクラスタ)が認識される
図:Veeam ONEにサーバ(HAクラスタ)が認識される
- 3.Analytics Serviceの導入
自動的に各ノードにエージェントがインストールされます。
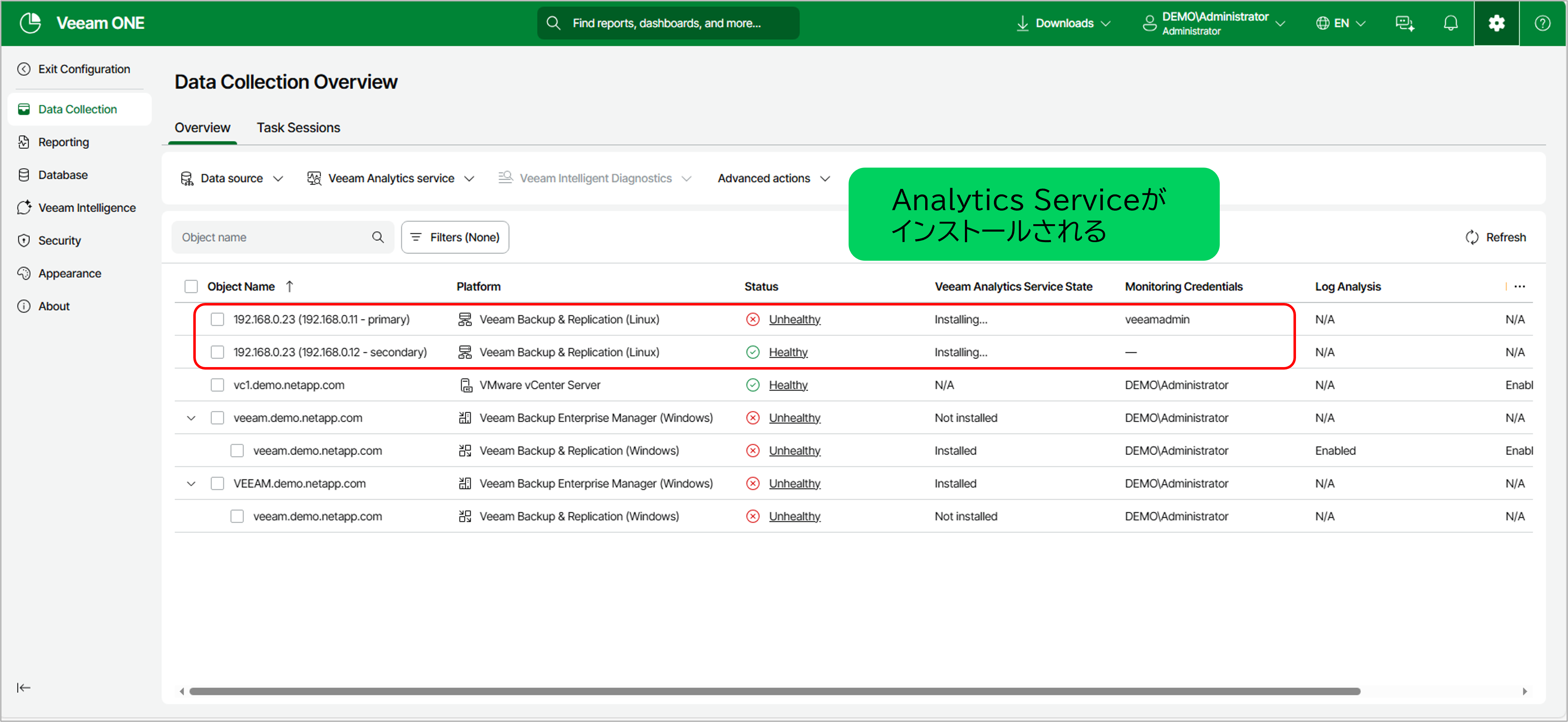 図:Analytics Serviceインストール中
図:Analytics Serviceインストール中
3-2. アラーム設定
自動フェイルオーバーを作動させるには、Veeam ONEのアラーム定義で「Remediation Action(修復アクション)」を設定する必要があります。
今回は検証のため、サーバー接続エラー系のアラームに対して、アクションとして「Perform failover」が実行されるように設定しました 。
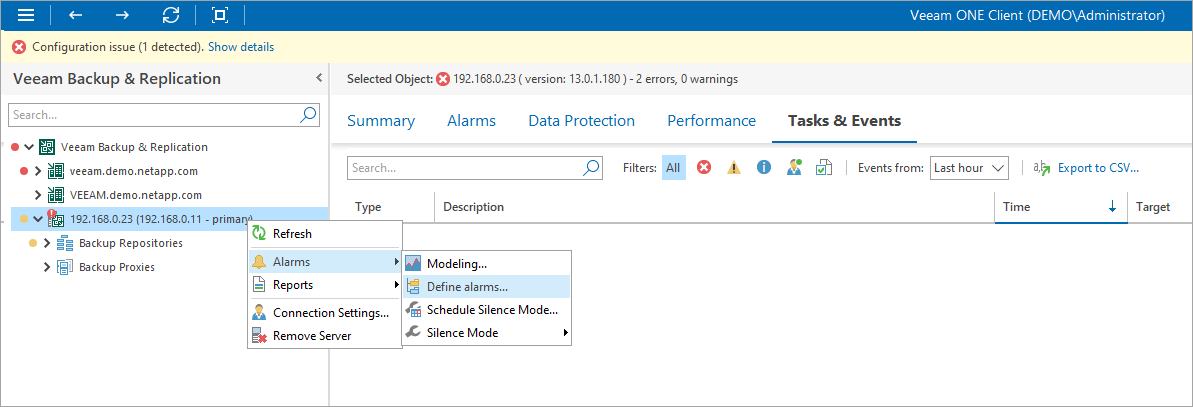 図:HAクラスタのアラームを設定
図:HAクラスタのアラームを設定
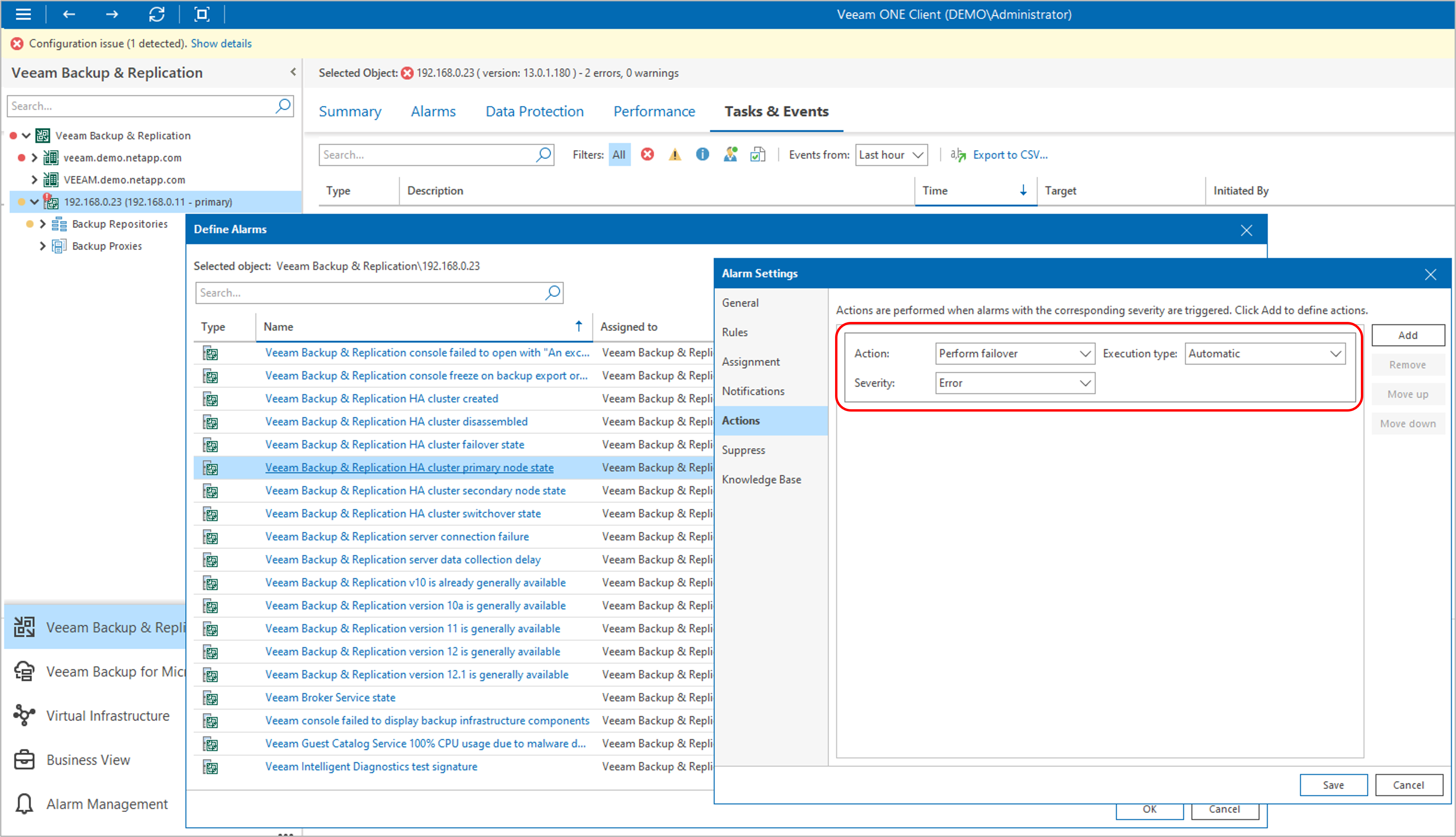 図:アクションを設定
図:アクションを設定
4. 障害テストと「スプリットブレイン」の発生
実際にプライマリノード(vsa13a)のVMをサスペンドさせ、擬似的な障害を発生させてみました。
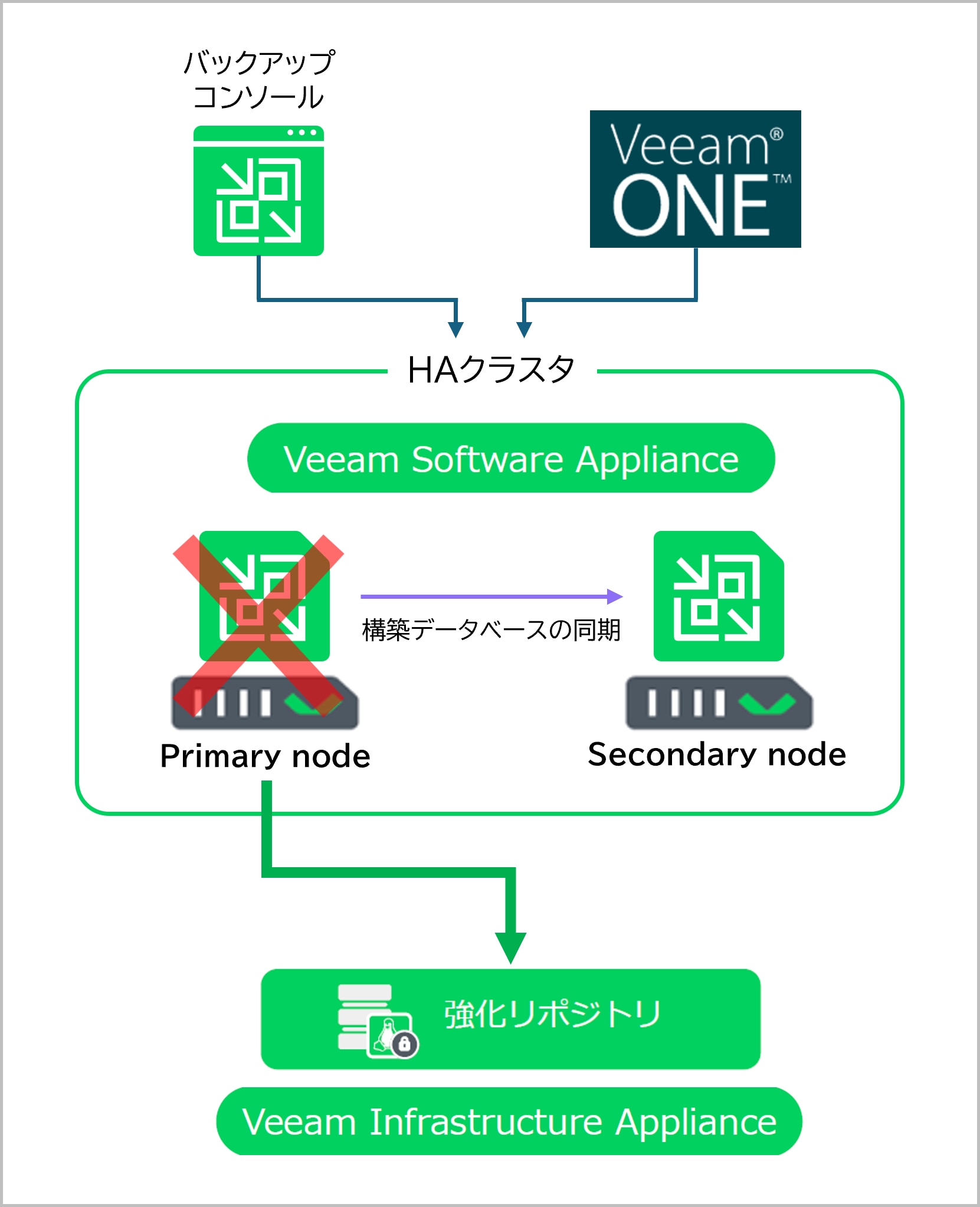
図:検証構成図(Primary Nodeで疑似障害発生中)
- 障害テストの結果
Veeam ONEがアクセス不可を検知し、スクリプトが発動。「Perform failover」アクションが実行されました 。
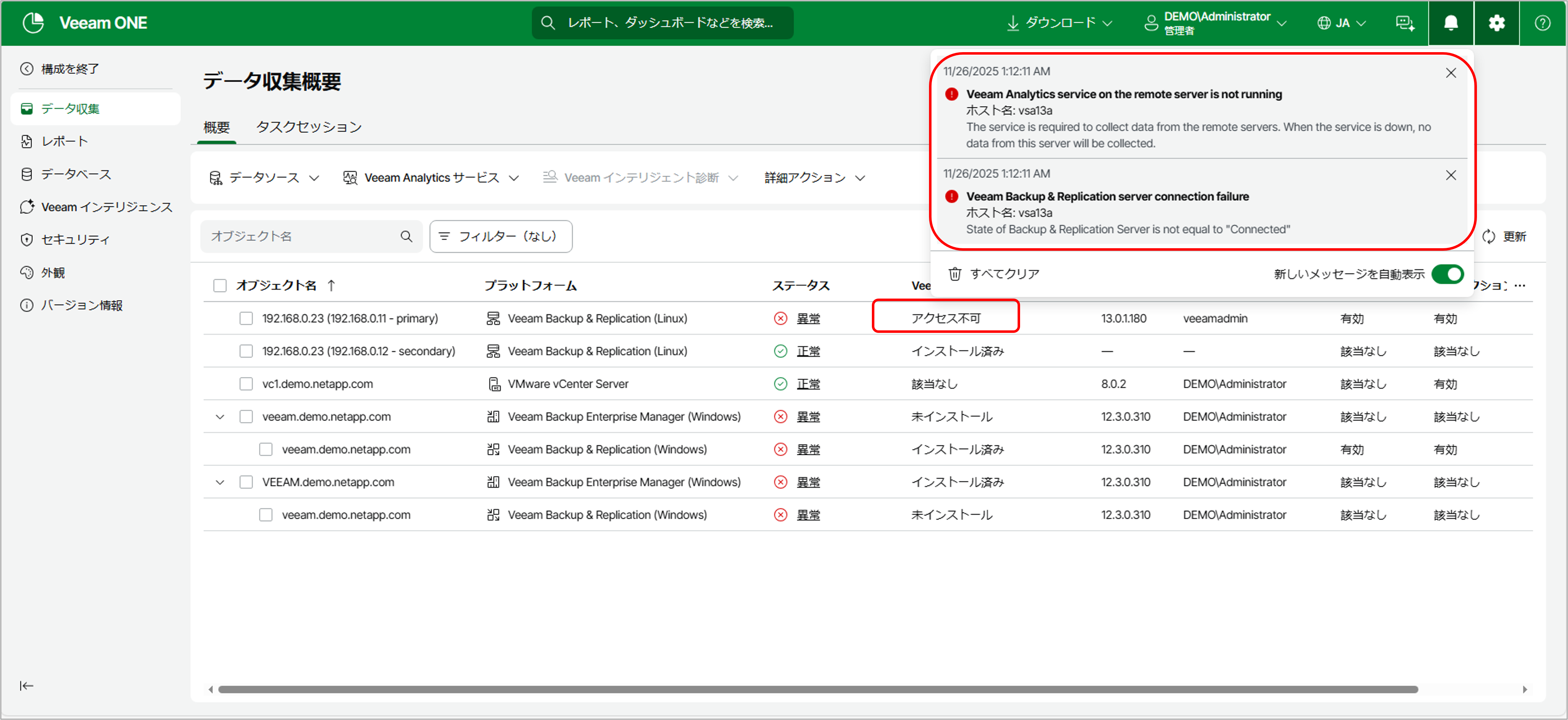 図:VeeamONEでアクセス不可を検知
図:VeeamONEでアクセス不可を検知
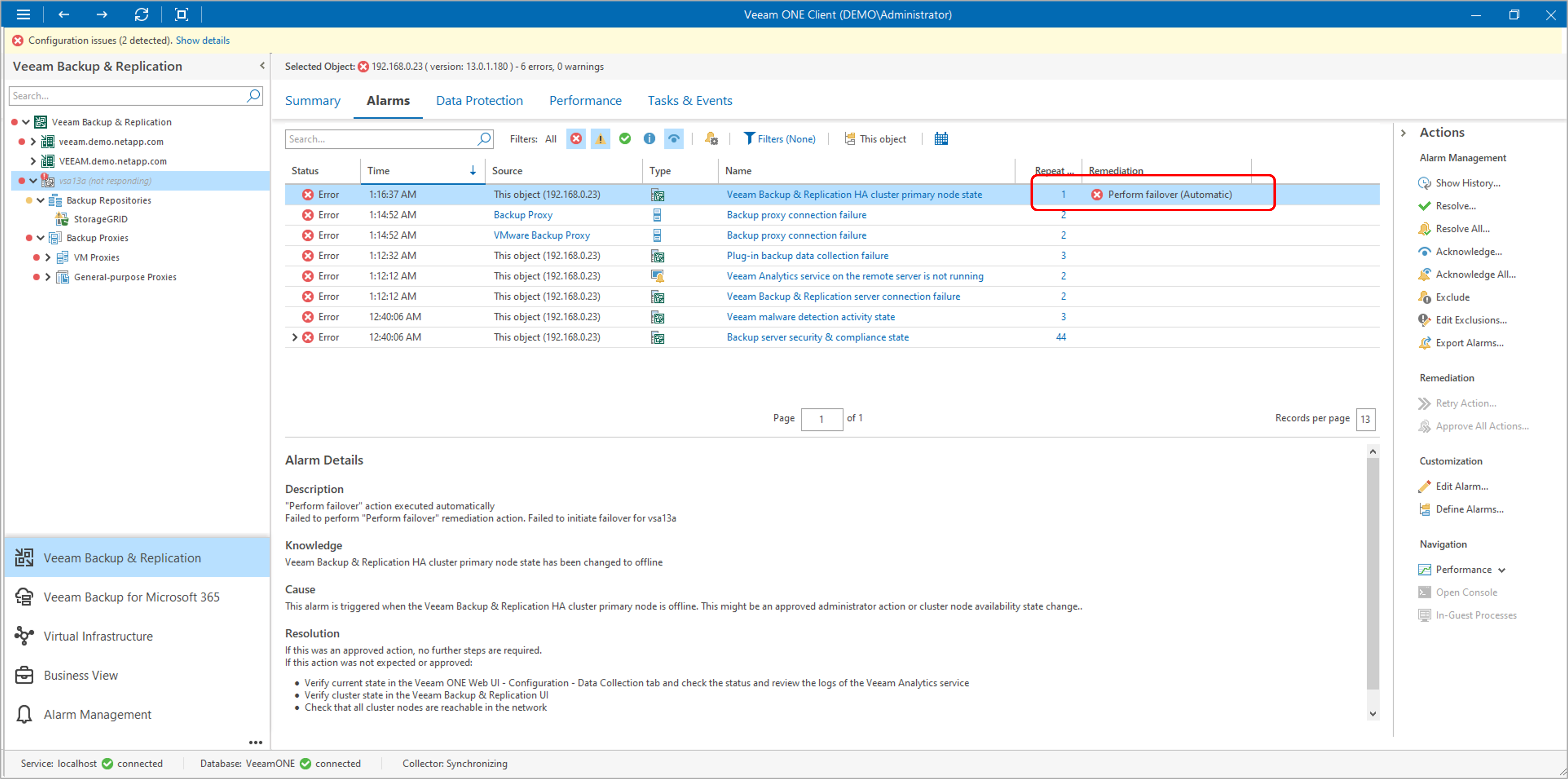 図:『自動フェールオーバー』が実行されたことを確認
図:『自動フェールオーバー』が実行されたことを確認
しかし、ここで課題が発生しました。
フェイルオーバー自体は試行されたものの、その後、旧プライマリノード(vsa13a)を復旧(レジューム)させたところ、「スプリットブレイン」状態 に陥りました。
- VBRコンソール : vsa13b(新プライマリ)がプライマリと認識
- Veeam ONE : vsa13a(旧プライマリ)がプライマリと認識
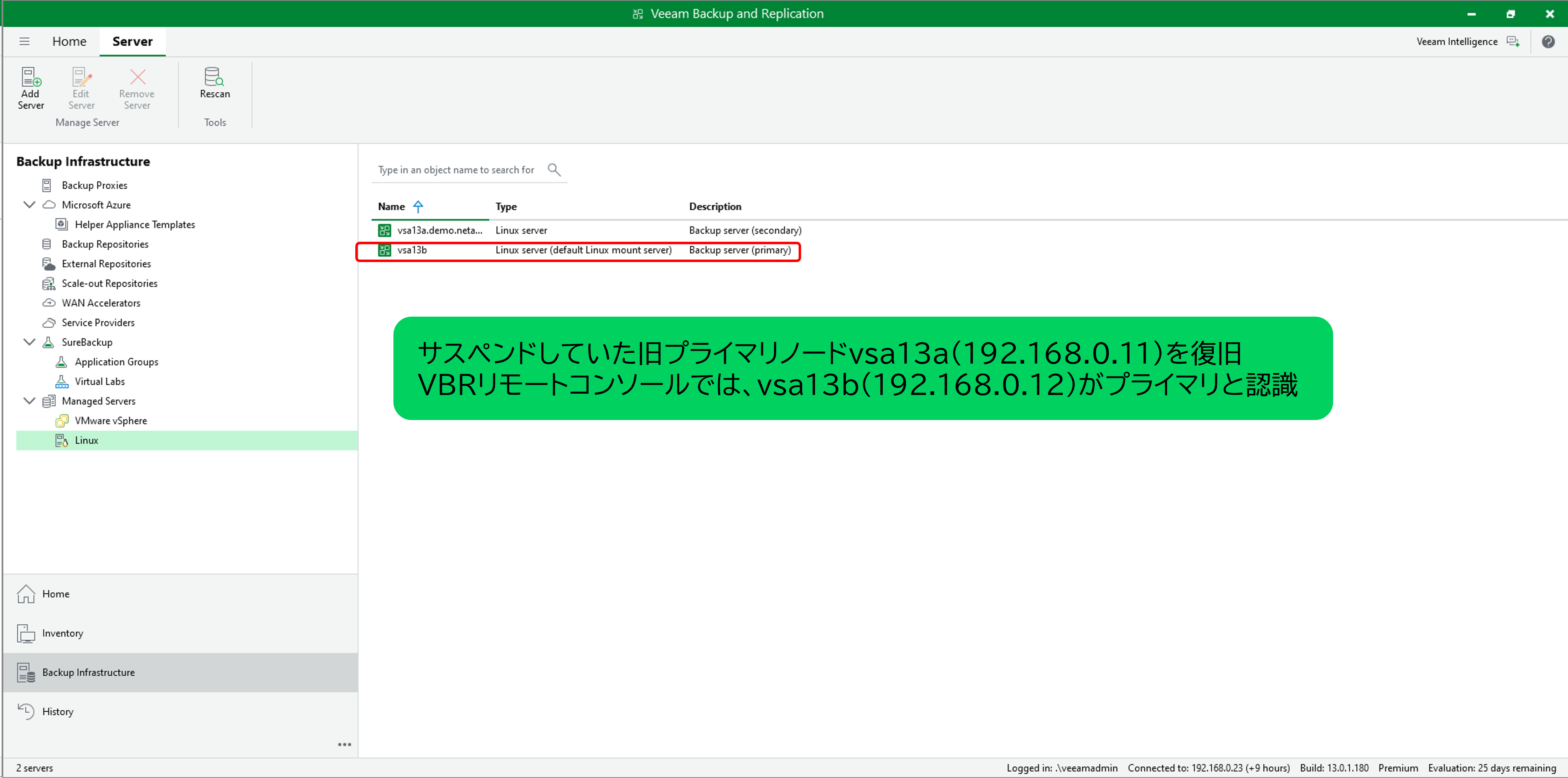 図:VBRコンソールではvsa13bをプライマリと認識
図:VBRコンソールではvsa13bをプライマリと認識
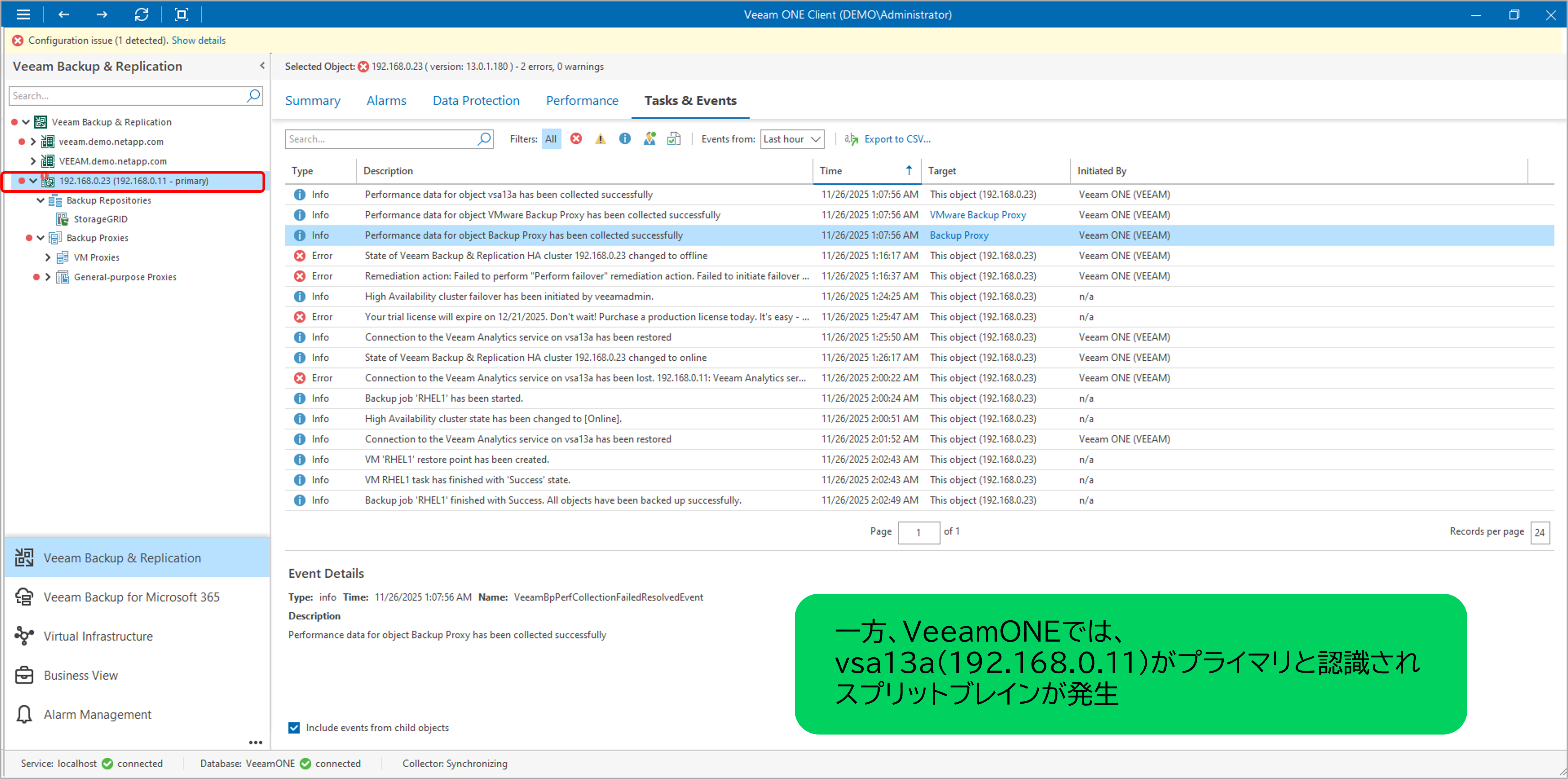 図:VeeamONEではvsa13aがプライマリと認識
図:VeeamONEではvsa13aがプライマリと認識
Veeamのマニュアルには「Split Brain Resolution Algorithm」によって、旧プライマリが復帰した際に新プライマリへ問い合わせて状態を更新する仕様が記載されていますが 、今回の検証ケースではうまく同期せず、クラスタの再構築が必要になるケースがあることが分かりました 。
5. まとめと今後の期待
Veeam v13のSoftware ApplianceによるHA構成は、アプライアンスだけで冗長化が組める非常に強力な機能です。
Veeam ONEと組み合わせることで、運用の自動化も視野に入ってきました。
正常終了や切り替えのためのクラスタ一括停止コマンド(Nutanixの "cluster stop" のようなもの)が実装されると、計画停止時の運用がより楽になるのでは、と感じました。
- 今回の検証からの学び
- 構築時はローカルリポジトリの削除を忘れずに。
- 自動フェイルオーバー設定時は、どのアラームで発動させるか慎重な設計が必要(過敏に反応するとスプリットブレインのリスクも)。
まだリリースされたばかりの機能ですので、今後のアップデートでスプリットブレイン対策や運用コマンドがさらに洗練されていくことを期待します。
本記事は検証環境での結果に基づいています。本番環境への導入時は、十分な検証を行ってください。



